设为首页
收藏本站
用户名
Email
自动登录
找回密码
密码
登录
立即注册
快捷导航
用户
论坛
BBS
元宝论坛
»
论坛
›
元宝论坛
›
现代
›
《处理器微架构实现》笔记(四):执行 ...
返回列表
查看:
79
|
回复:
0
《处理器微架构实现》笔记(四):执行
[复制链接]
水起风声
水起风声
当前离线
积分
6
2
主题
5
帖子
6
积分
新手上路
新手上路, 积分 6, 距离下一级还需 44 积分
新手上路, 积分 6, 距离下一级还需 44 积分
积分
6
发消息
发表于 2022-9-21 16:18:39
|
显示全部楼层
|
阅读模式
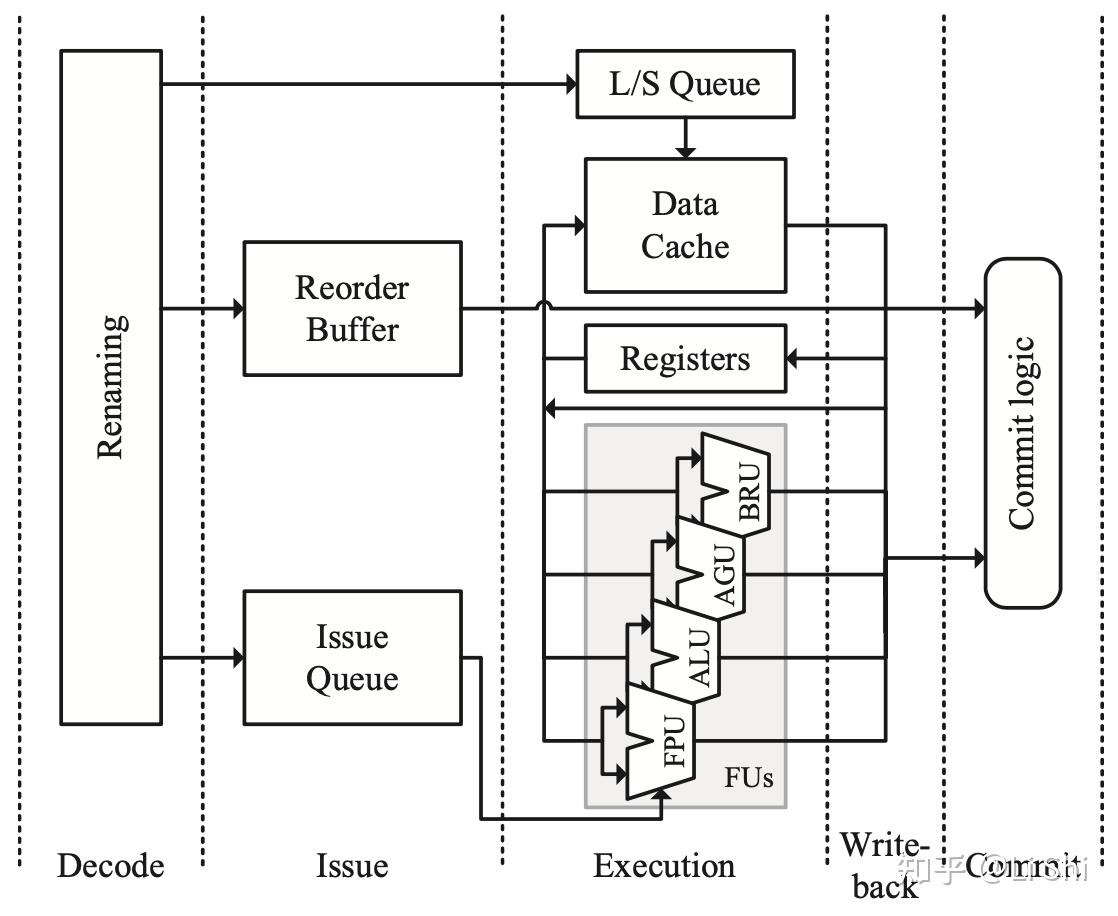
处理器执行单元
执行阶段真正开始执行一条指令的计算,包括算术操作、访存、分支等,大多数乱序处理器都会采用上图中的执行单元组织结构,灰色阴影区域表示功能单元(FU),如FPU进行浮点运算,ALU进行整数的算术和逻辑运算等。除此之外,执行阶段的另一个重点是旁路网络,以支持指令背对背执行。
功能单元
整数算术和逻辑单元(ALU)
ALU对两个整数输入进行操作,并产生一个整数结果。一些复杂的指令集在进行运算时还需要设置额外的标志位等,如x86。
整数乘法和除法
虽然也是整数操作,但由于乘法器或除法器的复杂性较高,通常被分离出来作为单独的执行单元。此外为了节省面积和功率,有些处理器使用浮点单元来执行整数乘法和除法, 如Intel Atom处理器。
地址生成单元(AGU)
AGU的目的在于为一个访存操作生成对应的地址。现代处理器通常有两种内存模型:线性和分段。
在线性内存模型中,内存表现为一个单一的连续地址空间。在分段内存模型中,内存对程序来说是很多段的集合,一锅端定义了一个从段基地址开始的连续地址空间,程序通过逻辑地址来访问内存,一个逻辑地址包括一个段的标识符和一个段内偏移量,程序的逻辑地址需要由硬件转换为线性地址。
在最复杂的x86指令集中,有六种不同的寻址模式,地址的计算由以下元素组成:
Displacement:立即数,即访问内存地址的常数偏移量。
Base:一个通用寄存器的值。
Index:一个通用寄存器的值。
Scale: 常数1、2、4或8,乘上Index得到偏移量。
地址的计算由如下公式表示:
Offset = Base + (Index * Scale) + Displacement
除了计算地址之外,AGU还需要检查偏移量是否在段的边界内。由此可见,x86计算地址非常复杂,在高频率下通常无法在一个周期内完成,可以切分成多级流水线,或者把地址的计算拆分成多个微指令。
分支单元
分支单元负责执行控制流指令,并产生正确的下一条指令地址,可以是有条件的或无条件的。
浮点单元(FPU)
FPU对来自浮点寄存器堆或内存的两个浮点值进行操作,并产生一个浮点结果,也可以进行浮点和整数之间的转换。FPU通常非常复杂,如在Pentium Pro上,FPU的面积和2个AGU、1个ALU、1个整数乘法器和1个整数除法器的总面积相同。
SIMD单元
SIMD即单指令多数据,在一组元素上并行执行相同操作。SIMD可以指早期一条指令处理包括大量元素的向量(对应RISC-V中的V扩展),也可以指现代处理器上的短向量(对应RISC-V中的P扩展),长度为4-16个元素。目前最流行的SIMD指令集是x86的SSE等,为x86指令集定义了16个新的SIMD寄存器,每个寄存器宽度128 bits。每个寄存器可以表示:
A vector of 16 byte-sized (8b) elements.
A vector of 8 word (16b) integer elements.
A vector of 4 doubleword (32b) integer elements.
A vector of 2 quadword (64b) integer elements.
A vector of 4 single-precision floating-point (32b) elements.
A vector of 2 double-precision floating-point (64b) elements.
旁路网络
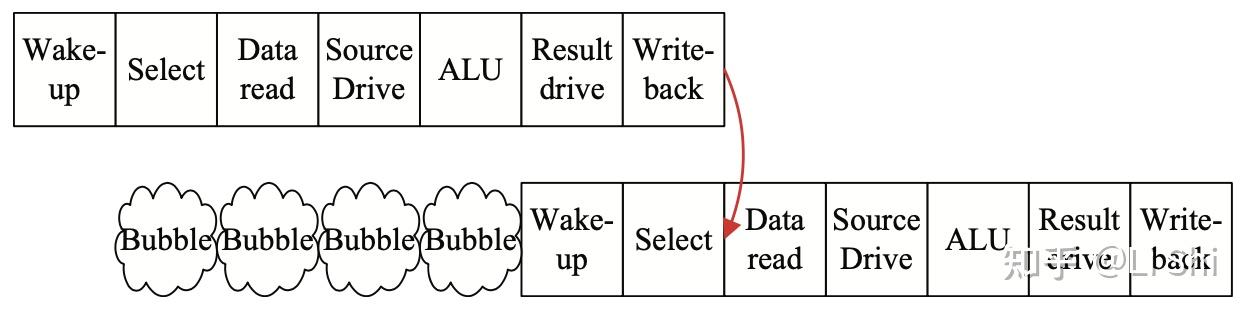
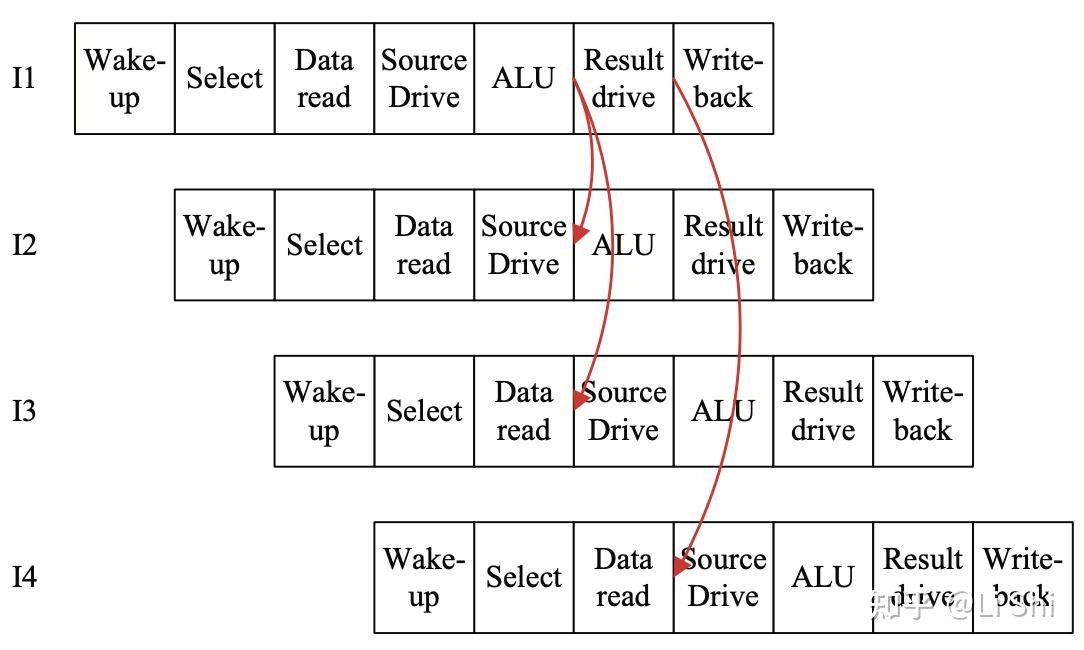
在五级流水线中,旁路网络可以减少由于数据依赖引起的停顿,这一概念在流水线级数更多的乱序处理器中显得更为重要。如果没有旁路网络,会产生下图所示的大量气泡,严重影响性能。
乱序流水线中存在数据依赖的两条指令
根据流水线设计的不同,旁路网络可以相对简单,也可以非常复杂,其设计直接影响到执行阶段的面积、功耗、关键路径和物理布局,需要有大量的权衡和取舍。复杂的旁路网络可以提升IPC,但是会影响关键路径和/或功耗。
乱序流水线中的数据前递
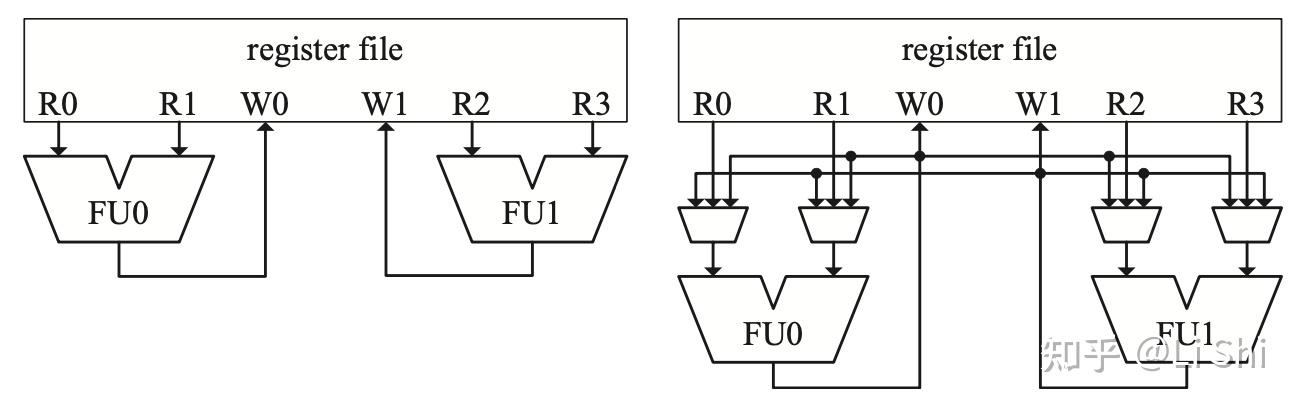
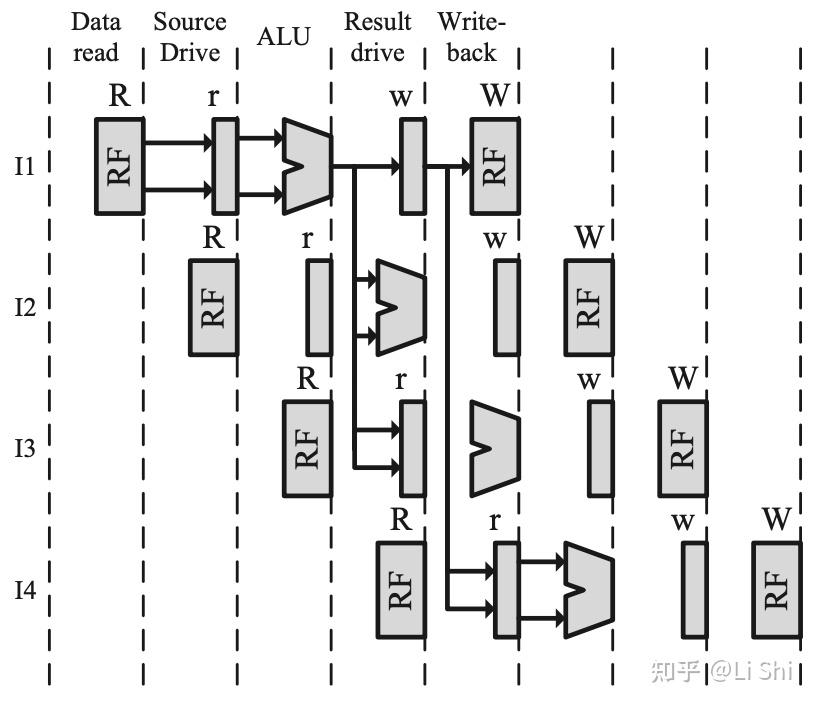
两个FU的执行单元
在没有旁路的情况下,FU的输入直接连接到RF的读端口,输出直接连到写端口。如果要加上旁路,每个FU的输入都要加上一个3-to-1的Mux。当设计的复杂度上升,旁路网络的复杂性也很快随之上升。一图胜千言,以下几张图直观地说明了旁路网络的设计及其效果。
两个FU的执行单元,但流水线级数更多
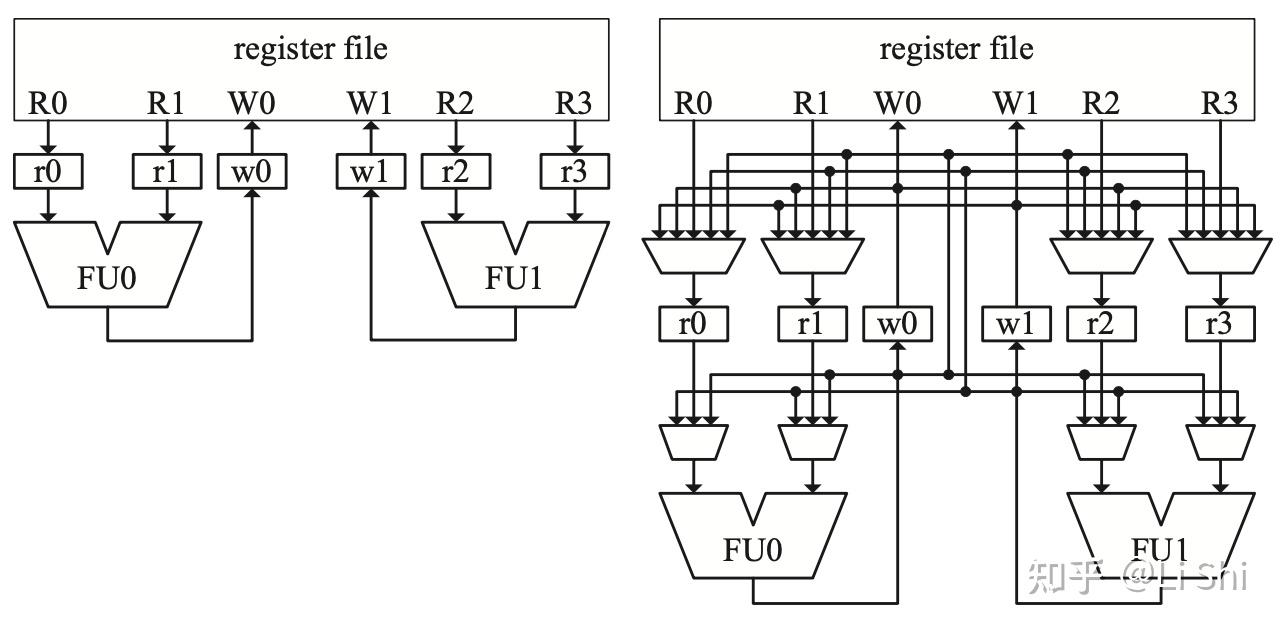
数据前递路径
数据前递路径
顺序流水线中的数据前递
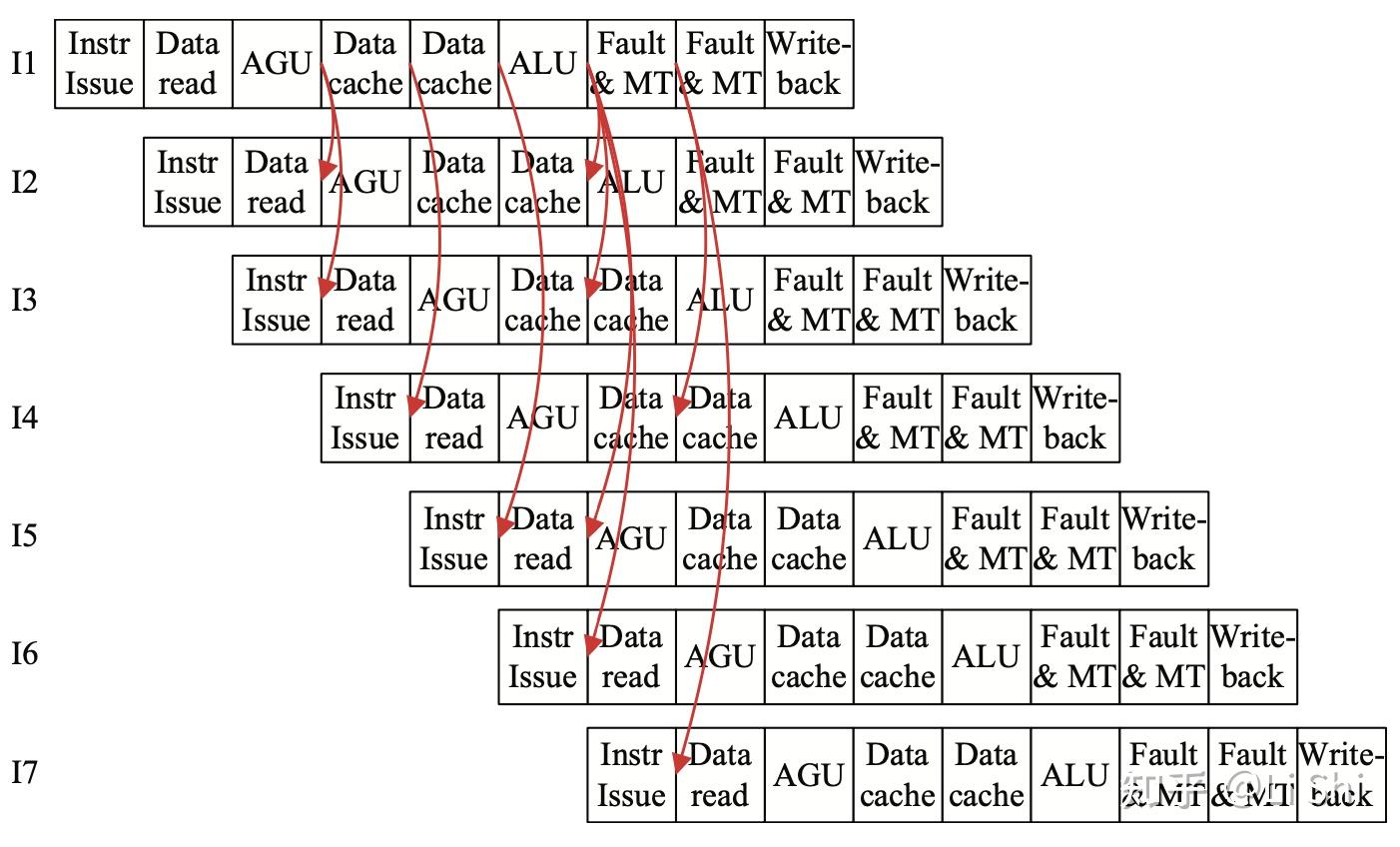
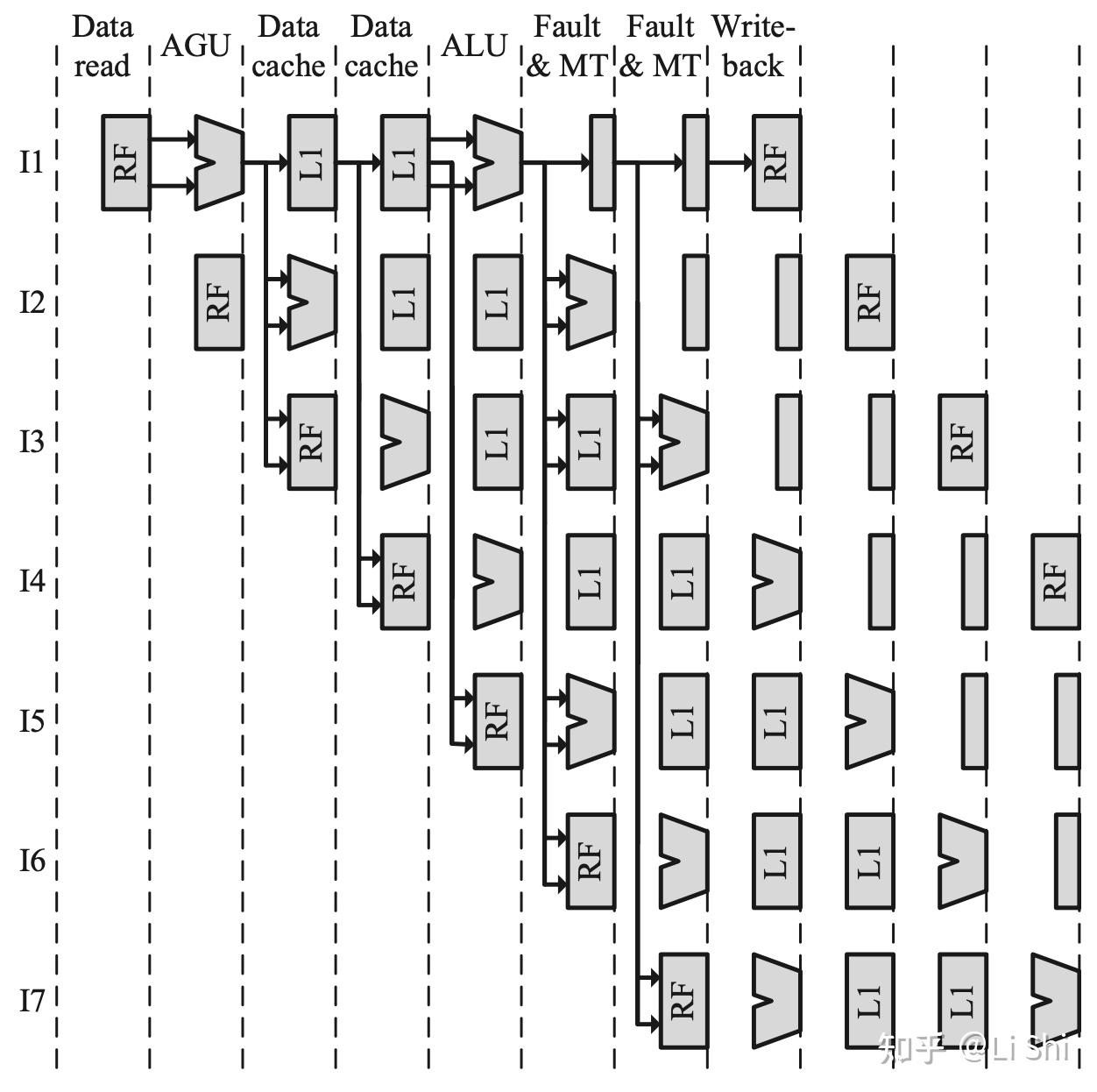
顺序流水线的旁路网络设计不一定比乱序更简单,下面几张图展示了Atom处理器的流水线与可能存在的数据前递路径。
Intel Atom顺序流水线中的可能存在的数据前递路径
Intel Atom顺序流水线中的可能存在的数据前递路径
分组
一个已经被证明有效的设计理念是在可行的情况下对关键硬件组件的布局进行分组,在不牺牲并行性的情况下尽可能提高可扩展性,如缓存设计中的阵列复制、分布式的发射队列等。
旁路网络的分组
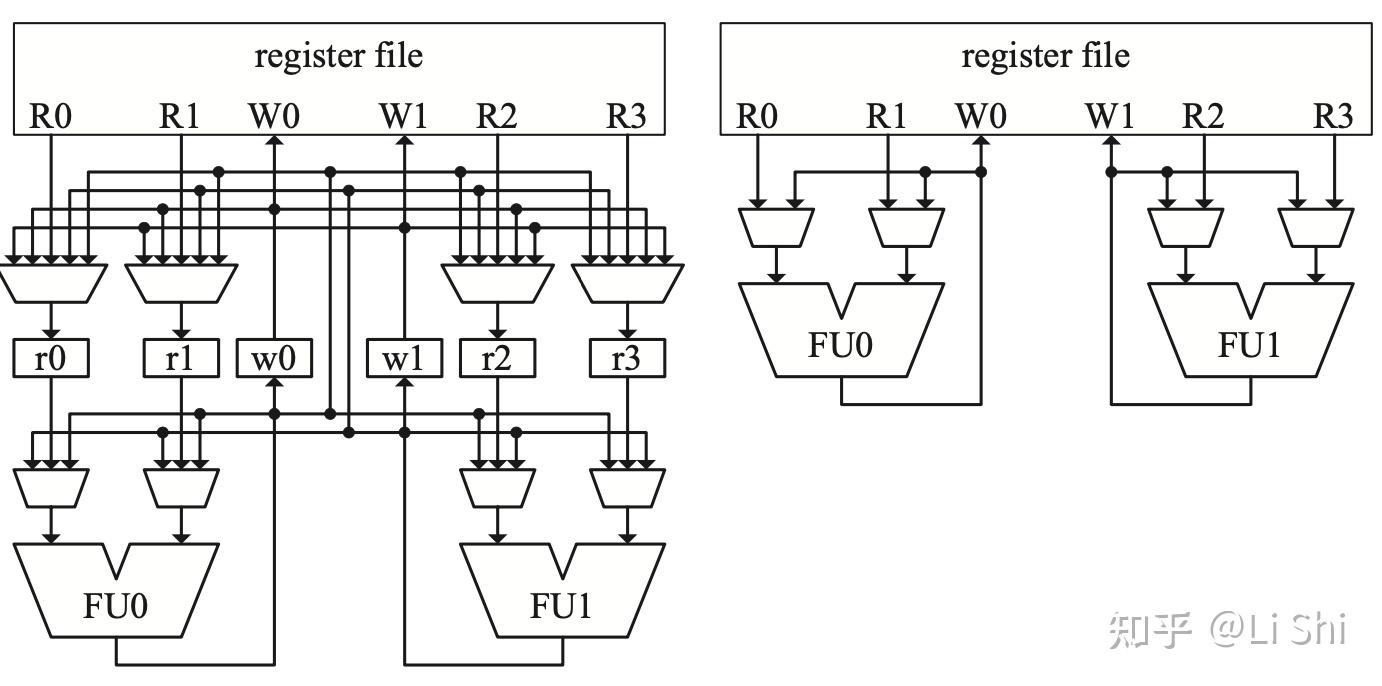
下图展示了旁路网络的分组,FU0的结果不允许转发到FU1,牺牲了一定性能但是大大简化了电路。
分组可以简化旁路网络
寄存器堆复制的分组
随着寄存器堆的读写端口数量的增加,访问延迟也会增加,可以通过分组设计解决这个问题。具体设计如下图,Alpha 21264采用这种设计,可以大大简化旁路的设计,并达到在当时看来非常高的时钟频率。
简化的Alpha 21264执行单元,采用了寄存器堆复制的分组
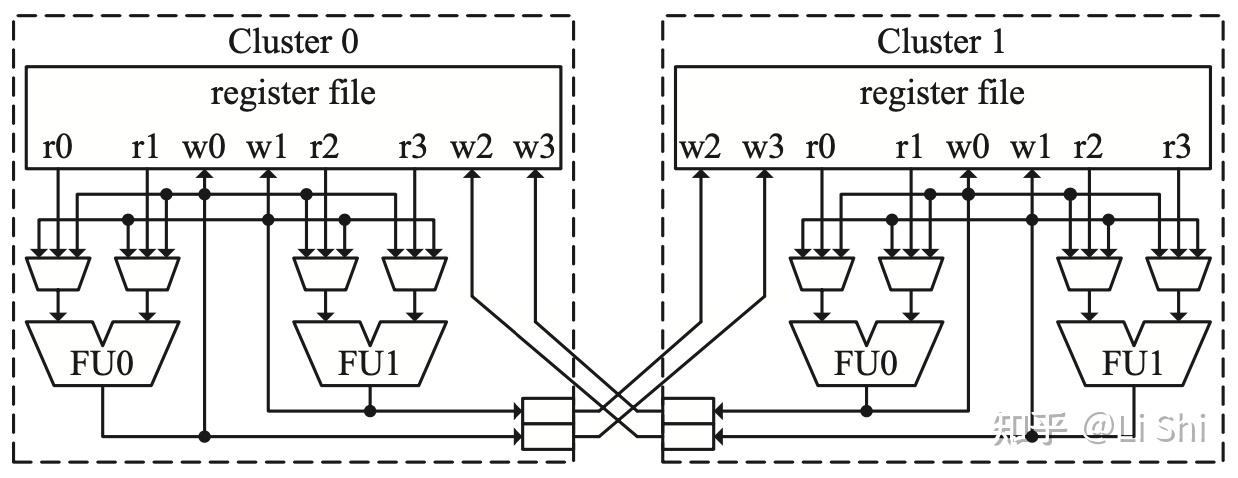
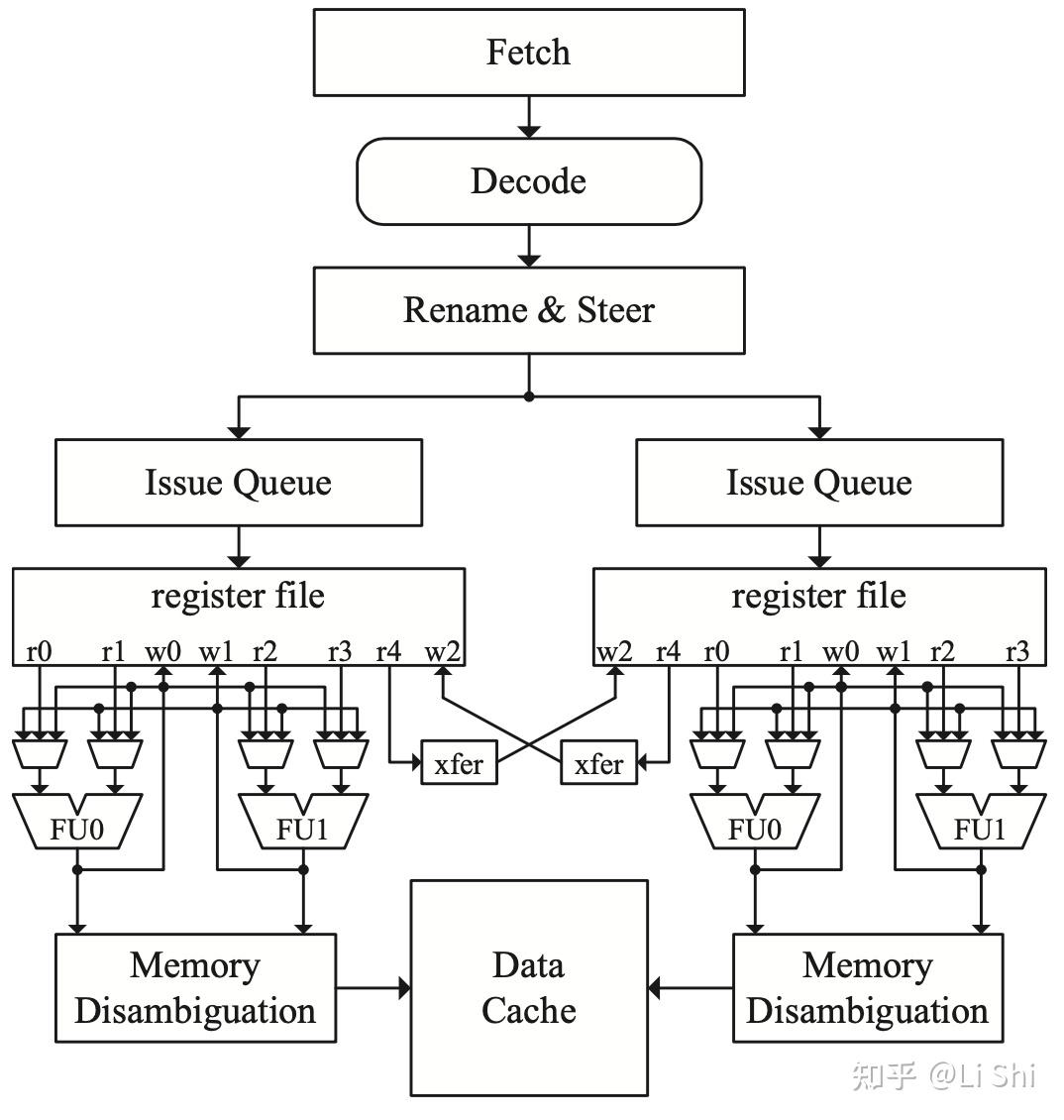
分布式队列和寄存器堆的分组
在这种设计中,寄存器堆不是复制,而是分布式的分组,每组的大小都是原来的一半(包括端口数量和寄存器堆大小),这种设计也将整个执行单元、发射队列和逻辑进行了分配。这种架构提供了明确的机制来把数据从一个寄存器堆传送到另一个寄存器堆。这种类型的分组结构另一个特点是,发射队列也是分布式的,在分配阶段,指令就会被分派到不同的分组中,这个过程称为instruction steering。这种设计降低了功耗和复杂性,但是也提升了instruction steering的设计复杂度。具体的流水线如下图所示。
包含了两个寄存器堆与发射队列的分组设计
回复
使用道具
举报
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
快速回复
返回顶部
返回列表



 发表于 2022-9-21 16:18:39
发表于 2022-9-21 16:18:39